In this project, I will be utilizing data from the Internet Movie Database (IMDb) to discover what the next best movie is to produce. Before settling on my decision, I will dive into Hollywood’s history to identify key characteristics of successful movies, identify successful directors and actors, and examine some of Hollywood’s most famous flops. With all this information compiled together, I will pick a crew and a movie to remake, and then pitch the idea to the higher ups at my company.
Diving into the Data
Firstly, I must download the data of Hollywood’s history into my rstudio. Since there were a sizable amount of people recorded in the industry, I decided to restrict my attention to people with at least two “known for” credits. This all can be seen in the folded code below:
Click here to see how the data was downloaded
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Rows: 771476 Columns: 6
── Column specification ────────────────────────────────────────────────────────
Delimiter: "\t"
chr (6): nconst, primaryName, birthYear, deathYear, primaryProfession, known...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
TITLE_BASICS <-get_imdb_file("title.basics")
Warning: One or more parsing issues, call `problems()` on your data frame for details,
e.g.:
dat <- vroom(...)
problems(dat)
Rows: 4729628 Columns: 9
── Column specification ────────────────────────────────────────────────────────
Delimiter: "\t"
chr (8): tconst, titleType, primaryTitle, originalTitle, startYear, endYear,...
dbl (1): isAdult
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
TITLE_EPISODES <-get_imdb_file("title.episode")
Rows: 8585773 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: "\t"
chr (4): tconst, parentTconst, seasonNumber, episodeNumber
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
TITLE_RATINGS <-get_imdb_file("title.ratings")
Rows: 1490875 Columns: 3
── Column specification ────────────────────────────────────────────────────────
Delimiter: "\t"
chr (1): tconst
dbl (2): averageRating, numVotes
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
TITLE_CREW <-get_imdb_file("title.crew")
Rows: 10521826 Columns: 3
── Column specification ────────────────────────────────────────────────────────
Delimiter: "\t"
chr (3): tconst, directors, writers
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
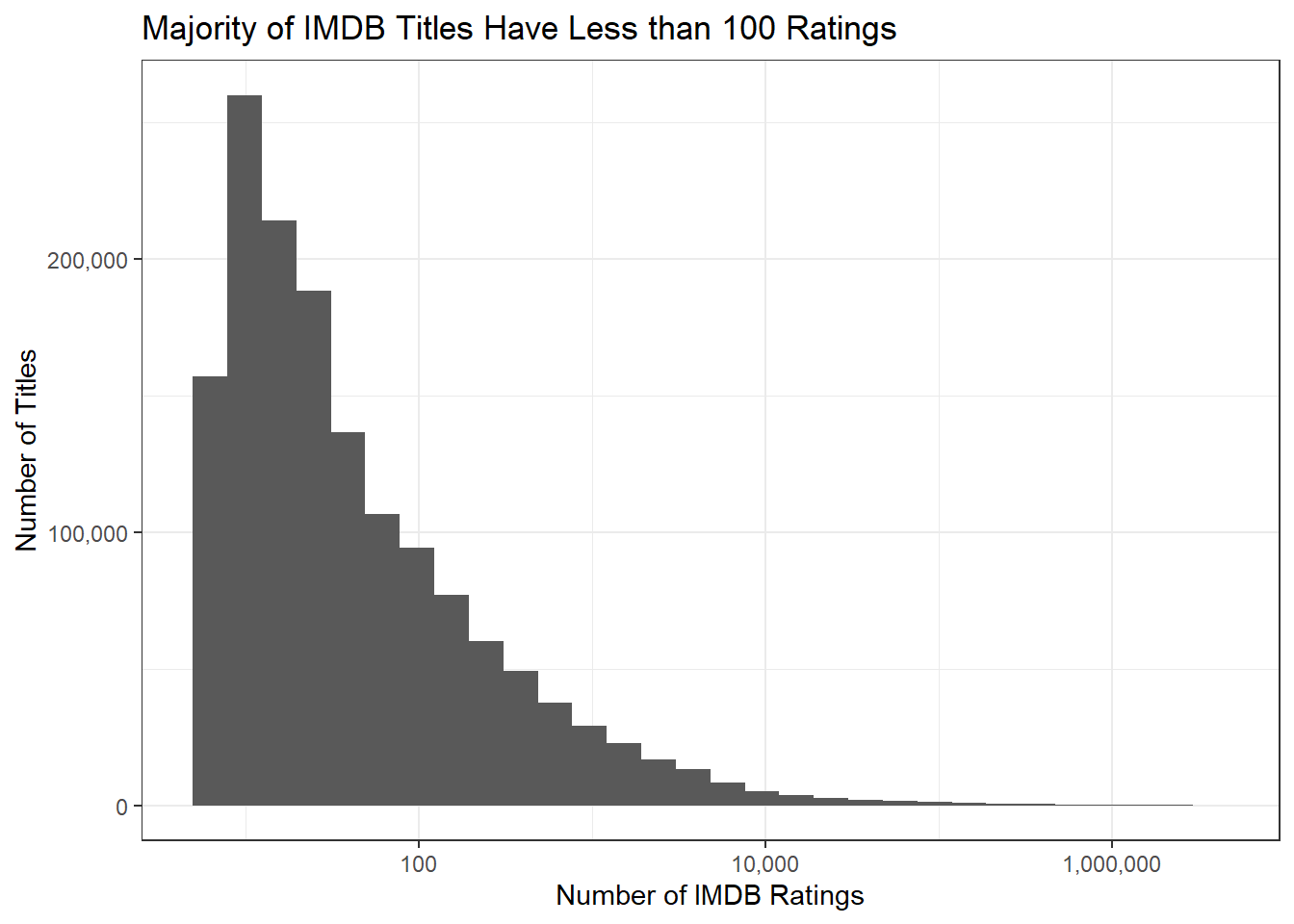
Now that I restricted the worker’s data set, I am curious to see how many obscure movies are in my data, as I want to avoid creating a low selling movie. Below is a chart that depicts the number of titles in comparison to their number of IMDb ratings.
TITLE_RATINGS |>ggplot(aes(x=numVotes)) +geom_histogram(bins=30) +xlab("Number of IMDB Ratings") +ylab("Number of Titles") +ggtitle("Majority of IMDB Titles Have Less than 100 Ratings") +theme_bw() +scale_x_log10(label=scales::comma) +scale_y_continuous(label=scales::comma)
Here, we can see the a majority of the movies in this data set have less than 100 ratings. To limit my data set further, I threw out any title that had less than 100 ratings. Looking at the quarterly ranges below, this shows that this drops about 75% of our data.
TITLE_RATINGS |>pull(numVotes) |>quantile()
0% 25% 50% 75% 100%
5 11 26 100 2954275
So, I performed this drop by performing the following code:
Now that our data has been significantly reduced, we can move on!
Task 1: Column Type Correction
After performing the glimpse function to examine each table, it was clear that some columns appeared as “character (string)” vectors, when they should be numeric. This is due to the null or N/A values that appears in the data sets. Since R cannot read these files as is, we must mutate the tables in a way that R can read them numerically. This is done with the following code:
Warning: There were 2 warnings in `mutate()`.
The first warning was:
ℹ In argument: `birthYear = as.numeric(birthYear)`.
Caused by warning:
! NAs introduced by coercion
ℹ Run `dplyr::last_dplyr_warnings()` to see the 1 remaining warning.
Warning: There were 3 warnings in `mutate()`.
The first warning was:
ℹ In argument: `endYear = as.numeric(endYear)`.
Caused by warning:
! NAs introduced by coercion
ℹ Run `dplyr::last_dplyr_warnings()` to see the 2 remaining warnings.
Warning: There were 2 warnings in `mutate()`.
The first warning was:
ℹ In argument: `seasonNumber = as.numeric(seasonNumber)`.
Caused by warning:
! NAs introduced by coercion
ℹ Run `dplyr::last_dplyr_warnings()` to see the 1 remaining warning.
Now that the data tables are cleaned up and ready to be used, I can begin to explore the data.
Task 2: Instructor-Provided Questions
Firstly, I want to find out how many movies are in our data set? How many TV series? And how many TV episodes?
nconst primaryName birthYear deathYear primaryProfession
1 nm0393833 William S. Hooser 1836 NA actor
knownForTitles
1 tt0157755,tt0015357,tt0408145
I quickly saw that the birth year of this person was 1836. So unless our oldest person is 188 years old, we need to put a restraint on how far back their birth year is, in case their death was not recorded. Since the oldest living person in the world is 116, the earliest possible birth year can be 1908. Many individuals came up for this birth year, however once I Google searched the ten oldest people in the world, none of them were on that list. I even saw that a few of these names did have deaths recorded on Google, but not on the database. Since there are only about 500,000 living individuals over the age of 100, which is only about .007% of the population, I decided to set my birth range to 100 years ago. Though someone may be slightly older than this and still alive, I thought this would be a safe bet to assume.
nconst primaryName birthYear deathYear primaryProfession
1 nm0001693 Eva Marie Saint 1924 NA actress,producer,soundtrack
knownForTitles
1 tt0047296,tt0053125,tt0348150,tt1837709
Thus, I found that Eva Marie Saint is the oldest and still alive person in our database. Her career spanned over eighty years and she won numerous awards for her works. She was even born close to New York, in Newark, NJ!
Thirdly, there is one TV Episode in this data set with a perfect 10/10 rating and at least 200,000 IMDb ratings. I want to discover what episode this is and what show it belongs to.
To do this, I restricted my data to only show me these restraints. This can be seen in the following code:
From doing the commands above, I found that the only episode that reached these ratings was episode 14 of season 5 in Breaking Bad. Looking this up on Google, I found that the title of the episode was “Ozymandias.” This episode is rated so highly due to the brilliance of how show runners depicted the main protagonist getting everything taken away from him. Pivotal events happen, including a main character’s demise which became a significant turning point for the narrative. Over a decade later, this episode is still raved and talked about by fans.
Fourthly, what four projects is the actor Mark Hamill most known for?
nconst primaryName birthYear deathYear primaryProfession
1 nm0000434 Mark Hamill NA NA actor,producer,director
knownForTitles
1 tt0076759,tt2527336,tt0080684,tt0086190
tconst titleType primaryTitle originalTitle isAdult
1 tt0076759 movie Star Wars: Episode IV - A New Hope Star Wars FALSE
startYear endYear runtimeMinutes genres
1 1977 NA 121 Action,Adventure,Fantasy
tconst titleType primaryTitle
1 tt0086190 movie Star Wars: Episode VI - Return of the Jedi
originalTitle isAdult startYear endYear
1 Star Wars: Episode VI - Return of the Jedi FALSE 1983 NA
runtimeMinutes genres
1 131 Action,Adventure,Fantasy
tconst titleType primaryTitle
1 tt0080684 movie Star Wars: Episode V - The Empire Strikes Back
originalTitle isAdult startYear endYear
1 Star Wars: Episode V - The Empire Strikes Back FALSE 1980 NA
runtimeMinutes genres
1 124 Action,Adventure,Fantasy
Using the command above, I found that Mark Hamill was known for four Star Wars titles, including: Star Wars: Episode IV - A New Hope, Star Wars: Episode VIII - The Last Jedi, Star Wars: Episode V - The Empire Strikes Back, and Star Wards: Episode VI - Return of the Jedi.
Fifthly, I want to know what TV series, with more than 12 episodes, has the highest average rating?
primaryTitle total_episodes averageRating
1 Craft Games 318 9.7
print(highest_rating_series)
tconst titleType primaryTitle originalTitle isAdult startYear endYear
1 tt15613780 tvSeries Craft Games Craft Games FALSE 2014 NA
runtimeMinutes genres averageRating numVotes total_episodes
1 NA Adventure,Comedy,Family 9.7 151 318
Thus, I found out that Craft Games was the highest rated series with over 12 episodes, with an average rating of 9.7.
Lastly, I wanted to know more about the TV series Happy Days. The TV series Happy Days (1974-1984) gives us the common idiom “jump the shark”. The phrase comes from a controversial fifth season episode (aired in 1977) in which a lead character literally jumped over a shark on water skis. Idiomatically, it is used to refer to the moment when a once-great show becomes ridiculous and rapidly looses quality.
I want to know if it is true that episodes from later seasons of Happy Days have lower average ratings than the early seasons?
To do this, I must restrict my data set to only show me information about Happy Days. At first, I only restricted this by the name, but I quickly realized that there were numerous projects with the same name. Because of this, I also added the restrictions of the start year and end year of the series. By doing the following code, I find the necessary tconst that identifies the series. Then, I ran the following code to get the average rating of each season and compare them.
By looking at the table above, we can see that the scores did in fact drop towards the later seasons, with Season 8 being the lowest scoring season. For the first half of the show, they average at a high 7 rating, but a downward decline began after season 3. Season 11, which was their final season, inevitably scored back in the 7 range, but the score still did not beat any from the first four seasons.
Task 3: Custom Success Metric
For my success metric, I decided to create a scale that assesses the total popularity of a work. To do this, I decided to multiply the average rating that it got by the number of votes. My logic is that a work cannot be successful without each of these metrics: a low scoring average with a lot of votes means that the movie flopped and a high scoring average with no votes means that the movie is too obscure. However, if a movie is averaged highly and has a lot of votes, this means that it is widely known and highly regarded. Thus, I believe that this is an accurate way to measure success.
To test my theory, I will run some tests to see if it holds up against actually highly regarded movies and some of the more obscure ones in Hollywood.
Firstly, I will choose the top ten movies on my metric and confirm that they were box office successes.
Click here to see how I filtered my data to show this
tconst titleType primaryTitle
1 tt0111161 movie The Shawshank Redemption
2 tt0468569 movie The Dark Knight
3 tt1375666 movie Inception
4 tt0137523 movie Fight Club
5 tt0109830 movie Forrest Gump
6 tt0110912 movie Pulp Fiction
7 tt0816692 movie Interstellar
8 tt0068646 movie The Godfather
9 tt0120737 movie The Lord of the Rings: The Fellowship of the Ring
10 tt0133093 movie The Matrix
genres startYear averageRating numVotes popularity
1 Drama 1994 9.3 2954275 27474758
2 Action,Crime,Drama 2008 9.0 2935734 26421606
3 Action,Adventure,Sci-Fi 2010 8.8 2605397 22927494
4 Drama 1999 8.8 2386403 21000346
5 Drama,Romance 1994 8.8 2311754 20343435
6 Crime,Drama 1994 8.9 2268830 20192587
7 Adventure,Drama,Sci-Fi 2014 8.7 2179321 18960093
8 Crime,Drama 1972 9.2 2059556 18947915
9 Action,Adventure,Drama 2001 8.9 2052301 18265479
10 Action,Sci-Fi 1999 8.7 2097695 18249947
The following are the top ten successes on my list:
These all proved to be more obscure and poorly-rated movies. Therefore, the metric does work both ways.
Thirdly, now I will choose a prestige actor and confirm that they have many projects that score highly on my metric. For this, I decided to look into Tom Hanks and Leonardo DiCaprio, as I believe they are two major actors in the industry currently.
Click here to see how I filtered my data to show this
Here, we can see that the movies given back by my success metric are in fact box office successes. Movies such as Titanic, The Wolf of Wall Street, Cast Away, and Forrest Gump are all well-known movies that were incredibly well-rated. Thus, the metric still holds.
Fourthly, for my final test, I wanted to compare my metric with the highest-grossing movies of all time. After searching this data on Google, I found that some of the highest grossing movies of all time is Titanic with $2,264,750,694, Avatar: The Way of Water with $2,320,250,281, and Avatar with $2,923,706,026.
Click here to see how I filtered my data to show this
The chart below depicts three of the above movies. It is clear to see that the popularity score correlates with their gross, as both are high. This solidifies my success metric even further.
datatable(High_Grossing)
Lastly, now that my success metric has been solidified, I need to restrict my data set to only show me “successes.” To do this, I must distinguish a number that once a movie surpasses it in its “popularity” scale, then it is deemed a success. The number I decided to pick is 5,000,000, since I feel as though every great movie should be able to surpass that. Then, I reduced my data set to fit that benchmark using the following code.
Thus, the most successes per decade is as follows:
40s: Drama (1)
50s: Crime (1)
60s: Adventure (2)
70s: Drama (7)
80s: Action (8)
90s: Drama (25)
00s: Drama/Adventure (30)
10s: Action (21)
20s: Action (2)
Secondly, to see what genre had the most consistent “successes” and which one used to reliably produce “successes,” but has fallen off, I decided to create a data table. This way, all of the successful movies per genre throughout the decades can be easily visualized.
Below is a table that shows all of the genres throughout the years.
library(DT)datatable(decades)
Looking at the chart, it is clear to see that the genre with the most consistent successes each decade is Drama, as it is the only genre that had a least one success every decade from the forties until now. It also has gotten more successes recently, with its height being in the 2000s.
The genre that used to reliably produce successes, but has fallen out of favor is Crime, as it had many success from the 1970s to 2000s, entirely fell off in the 2010s with only three successes. However, since the 2000s, the Drama genre definitely fell off the most, going from 30 success to 14 to 3 per decade.
Thirdly, I want to know what genre has produced the most successes since 2010. By looking at the chart above, it is clear to see the genre with the most successes since 2010 is Action with 24 successes. The Adventure genre is closely behind that, with 21 successes.
However, I want to know if this genre has only produced the most successes because it genuinely has the highest rating, or if there were just an abundance of Action movies that have been created since then to contribute to the score. To do that, I used the following code:
Here, we can see that it ranked first on the total popularity list, but third on the amount of movies list. This shows that while this genre produces highly-rated movies, there is also a good amount of them being made. However, the drama genre is the most produced and is still below the action genre on total popularity, so this shows that each movie is more successful than others.
Lastly, the genre that has become more popular in recent years is definitely the Action genre. It had its first successful movie in the 1970s, while ten other genres had earlier successes, and still skyrocketed in later decades to get 66 total successes. Only two genres are ahead of the action genre, which is drama with 86 successes and adventure with 67 successes. However, since the 2000s, it has had 50 successes, which is only one behind the top spot for successes in that time frame, which is the adventure genre.
Based on my findings, I decided to choose an Action genre, as while it is the third most produced in the last decade, it had the highest popularity score. It surpasses the Drama genre on the list, which is big considering that the drama genre has 20 more successes than the action genre. This shows me that the drama genre only have this high of a popularity due to successes that they had, which means each success had to average at the lower end of the success scale. Though the adventure genre also did very well on both of these lists, I decided not to choose it as I fear it may begin to get overplayed, much like the Drama genre. However, the Action genre seems to be an up-and-coming one, as it already has more successes than the Adventure genre in the 2020s, and the same amount as the Drama genre. Thus, I believe this is our best bet for a successful movie.
Task 5: Key Personnel
Now that I have my target genre, I want to identify a few actors and one director to really anchor my project. To create a strong team, I want one prestigious actor who has many successes in many genres, and preferably at least one major success in the action genre. With this major name, I hope to bring in their major following and their broad skill set to perfect the movie. For my second actor, I want to pick someone who has been apart of a highly rated movie, but is still not widely recognized yet. I want someone who is up-and-coming, that can build a strong profile around being in this movie. Then, the connection with these two main leads should bring good publicity.
For my prestige actor, I want someone who has been in the industry for a good amount of time and that is older with some experience. Thus, I decided that I wanted my actor to be at least 40, but no older than 75.
Click here to see how I filtered my data to show this
Warning in instance$preRenderHook(instance): It seems your data is too big for
client-side DataTables. You may consider server-side processing:
https://rstudio.github.io/DT/server.html
One by one, I decided to go down the list of people to see what their top works were. This can be seen in the code below.
I decided against Orlando Bloom, since he had 4 successful movies, three of which were apart of the Lord of the Rings franchise, and one Pirates of the Caribbean. I want a more diverse actor, rather than someone who mainly dominates the same universe.
Hugo Weaving was similar, with three Lord of the Rings movies and one movie titled “V for Vendetta.” Rizzo would have been perfect… until I researched and found out he was the music producer on these projects, and not an actor. Same with Zimmer.
Finally, I got to my seventh person on the list, Leonardo DiCaprio. Not only did his top movies dominate different genres, including Crime, Drama, Thriller, Romance, Comedy, etc., his top movie was an Action/Adventure mixed genre. Also scoring highest on his list on the popularity scale, Inception became the fourth highest-grossing movie of 2010, with DiCaprio as the star of the movie. Thus, it was clear that he was my first pick actor.
Next, I wanted to find someone younger and more up-and-coming. Thus, I chose to restrict the age gap to someone less than 30 years old. I did this with the following code:
I quickly decided upon Tony Revolori, as he was high on the list and was in a Spiderman movie recently that did fairly well. When I looked him up, he had some breakout awards and is expected to become a lot bigger in the upcoming years, especially as the projects he is currently working on begin to roll out.
At this point of the project, I realized that I had a slight oversight and did not include any female actresses into the mix. So, I decided to pick another younger actor to add to my team.
By running this previous code, I found that Taylor Geare would be a perfect pick for the movie. Not only has she won one award and been in a few works recently, I discovered that she was also in Inception with Leonardo DiCaprio! At the time, she was five years old and she played Philipa, who was the daughter of DiCaprio’s character. I believe that this pairing can bring major publicity to our work, as fans of Inception will get to see this duo back together, especially in a way that Geare will be able to display her skills as an adult.
Now, I must find a director for my movie. Using the same technique as above, I began my search.
Warning in instance$preRenderHook(instance): It seems your data is too big for
client-side DataTables. You may consider server-side processing:
https://rstudio.github.io/DT/server.html
Coming in second on the list, Wally Pfister easily proved to be the strongest candidate for this movie. Not only did he score incredibly highly on this list, he also worked on major movies such as The Dark Knight, The Prestige, Transcendence, and much more. However, most notably, he also worked on Inception with Leonardo DiCaprio and Taylor Geare. A picture of DiCaprio and Pfister can be seen below.
Thus, not only have they all worked together in the past so they know each other/have good chemistry, they were also able to create a masterpiece of a movie before in the same genre we are aspiring to. This could stir a lot of good media, as it not seen very often that three people from a very successful movie team up again to work on a remake of another successful movie. Thus, I feel very confident about the potential team I have put together.
Task 6: Finding a Classic Movie to Remake
Now, I must find a classic movie in this genre to remake. I want to find a movie that has not been remade in the past 25 years, has a large number of IMDb ratings, has a high average rating, and has a fan base that wants a remake to happen. To do this, I must first filter my data sets to give me a movie that fits these first three restraints.
I want to look at what the top movies are in the action genre, however, I also want to stay away from remaking any Star Wars movies. Thus, coming in at number 14, I debating on remaking Léon: The Professional, however, when I looked up if fans wanted a remake, they seemed entirely opposed. Many fans believe the film is perfect as is and it would not do any justice for it to be remade today. Thus, I decided to keep looking.
At number 31, I found Die Hard, a movie made in 1988 about an NYPD cop that has to take matters into his own hands when a group of robbers take control of the building he is in, holding everyone hostage except for him.
When I looked up if fans would want a remake of Die Hard, numerous articles came up showing great approval for this. Some of these are linked below:
Thus, a Die Hard remake is the best bet for a successful action movie.
However, before we move further, our legal department must reach out to certain members of the original movie production to secure the rights for the project. So, let’s find out who is still alive from the original.
nconst primaryName birthYear deathYear
1 nm0000435 Daryl Hannah 1960 NA
2 nm0000631 Ridley Scott 1937 NA
3 nm0000707 Sean Young 1959 NA
4 nm0001026 Joanna Cassidy NA NA
5 nm0001579 Edward James Olmos 1947 NA
6 nm0003256 Joshua Pines NA NA
7 nm0003666 Debbie Denise NA NA
8 nm0007072 Katherine Haber 1944 NA
9 nm0022370 Vickie Alper NA NA
10 nm0029959 Tim Angulo NA NA
11 nm0045630 Michael Backauskas NA NA
12 nm0047460 Robert D. Bailey NA NA
13 nm0048193 Beau Baker 1953 NA
14 nm0048396 Don Baker NA NA
15 nm0049792 Peter Baldock 1949 NA
16 nm0081795 William Biggerstaff NA NA
17 nm0099156 Christian Boudman NA NA
18 nm0114926 Winnie D. Brown NA NA
19 nm0123746 Tom Burton NA NA
20 nm0137698 Elizabeth Carlon NA NA
21 nm0164425 Robert Clark NA NA
22 nm0172782 Alan Collis NA NA
23 nm0173645 Gary Combs 1935 NA
24 nm0180108 Peter Cornberg NA NA
25 nm0190038 Eugene Crum NA NA
26 nm0193345 Greg Curtis NA NA
27 nm0199344 Stephen Dane NA NA
28 nm0203343 Howard Brady Davidson NA NA
29 nm0213057 Lisa Deaner NA NA
30 nm0214303 Michael Deeley 1932 NA
31 nm0218540 Carolyn DeMirjian NA NA
32 nm0220984 Linda DeScenna 1949 NA
33 nm0238734 David Dryer 1943 NA
34 nm0244956 Syd Dutton 1944 NA
35 nm0252914 Bud Elam NA NA
36 nm0266684 Hampton Fancher 1938 NA
37 nm0270670 Jane Feinberg NA NA
38 nm0274928 Michael Ferriter NA NA
39 nm0280029 William E. Fitch NA NA
40 nm0281551 Linda Fleisher NA NA
41 nm0283845 Stephen Fog NA NA
42 nm0285893 Terence Ford 1945 NA
43 nm0290519 Chris Franco NA NA
44 nm0292476 Terry D. Frazee NA NA
45 nm0302091 Steve Galich NA NA
46 nm0302406 Joe Gallagher 1953 NA
47 nm0303421 Kurt P. Galvao NA NA
48 nm0312920 Michael Genne NA NA
49 nm0325242 Joyce Goldberg NA NA
50 nm0333849 David Grafton NA NA
51 nm0341454 Cary Griffith NA NA
52 nm0356040 Robert Hall NA NA
53 nm0362046 David R. Hardberger 1948 NA
54 nm0362257 Alan Harding NA NA
55 nm0367242 Graham V. Hartstone 1944 NA
56 nm0369220 Donald Hauer NA NA
57 nm0372264 Les Healey 1950 NA
58 nm0381500 Linda Hess NA NA
59 nm0384603 Richard L. Hill NA NA
60 nm0390897 Richard E. Hollander NA NA
61 nm0394803 Bob E. Horn NA NA
62 nm0404527 Gillian L. Hutshing NA NA
63 nm0438325 Michael Kaplan NA NA
64 nm0452191 Madeleine Klein 1946 NA
65 nm0453139 Crit Killen NA NA
66 nm0461802 Michael Knutsen NA NA
67 nm0487514 James Lapidus NA NA
68 nm0507809 Terry E. Lewis NA NA
69 nm0513924 Marci Liroff NA NA
70 nm0518430 Basil Lombardo NA NA
71 nm0519436 Ronald Longo NA NA
72 nm0523370 Stephanie Lowry NA NA
73 nm0560094 Linda Matthews NA NA
74 nm0570488 Tim McHugh NA NA
75 nm0573488 Gregory L. McMurry 1952 NA
76 nm0590114 Michael Mills NA NA
77 nm0616694 Donald Myers NA NA
78 nm0624443 Tony Negrete NA NA
79 nm0640384 John O'Connor NA NA
80 nm0649687 James F. Orendorff NA NA
81 nm0655669 Shirley Padgett NA NA
82 nm0672065 Peter Pennell 1939 NA
83 nm0672459 David Webb Peoples 1940 NA
84 nm0689279 Thomas R. Polizzi NA NA
85 nm0689332 George Polkinghorne NA NA
86 nm0689503 Tama Takahashi NA NA
87 nm0694138 Ivor Powell NA NA
88 nm0703436 David Q. Quick NA NA
89 nm0709588 Gary Randall NA NA
90 nm0711047 Karen Rasch NA NA
91 nm0722541 Victoria E. Rhodes NA NA
92 nm0728110 Richard Rippel NA NA
93 nm0745076 Jonathan Rothbart NA NA
94 nm0747438 Thomas L. Roysden 1944 NA
95 nm0761836 William Sanderson 1944 NA
96 nm0768102 Fumi Mashimo NA NA
97 nm0769731 Steve Schaeffer NA NA
98 nm0770435 John Scheele NA NA
99 nm0774039 Suzie Schneider NA NA
100 nm0775562 Richard Peter Schroer NA NA
101 nm0778771 John A. Scott III NA NA
102 nm0779860 Tom Scott 1948 NA
103 nm0791107 Victor A. Shelehov NA NA
104 nm0794135 Arthur Shippee 1948 NA
105 nm0811435 David L. Snyder NA NA
106 nm0816170 Tom Southwell NA NA
primaryProfession knownForTitles
1 actress,producer,director tt0083658
2 producer,director,production_designer tt0083658
3 actress,miscellaneous,director tt0083658
4 actress,producer,miscellaneous tt0083658
5 actor,producer,director tt0083658
6 visual_effects,editorial_department,director tt0083658
7 visual_effects,producer,miscellaneous tt0083658
8 miscellaneous,producer,actress tt0083658
9 miscellaneous tt0083658
10 visual_effects,cinematographer,camera_department tt0083658
11 visual_effects,editorial_department,editor tt0083658
12 visual_effects,director,writer tt0083658
13 sound_department,actor,miscellaneous tt0083658
14 visual_effects,camera_department,director tt0083658
15 sound_department,editorial_department,actor tt0083658
16 art_department,miscellaneous tt0083658
17 visual_effects,miscellaneous,editorial_department tt0083658
18 costume_department,costume_designer tt0083658
19 director,producer,animation_department tt0083658
20 visual_effects tt0083658
21 art_department,special_effects,make_up_department tt0083658
22 producer,production_manager,miscellaneous tt0083658
23 stunts,assistant_director,actor tt0083658
24 production_manager,assistant_director,producer tt0083658
25 special_effects tt0083658
26 special_effects,art_department tt0083658
27 art_department,art_director,production_designer tt0083658
28 transportation_department tt0083658
29 visual_effects tt0083658
30 sound_department,producer,miscellaneous tt0083658
31 actress tt0083658
32 set_decorator,production_designer,actress tt0083658
33 visual_effects,camera_department tt0083658
34 visual_effects,special_effects,writer tt0083658
35 visual_effects,camera_department tt0083658
36 actor,writer,director tt0083658
37 casting_director,casting_department,producer tt0083658
38 visual_effects,special_effects,editorial_department tt0083658
39 camera_department tt0083658
40 visual_effects tt0083658
41 visual_effects tt0083658
42 actor,assistant_director,camera_department tt0083658
43 camera_department tt0083658
44 special_effects tt0083658
45 special_effects,visual_effects,art_department tt0083658
46 sound_department,editorial_department,music_department tt0083658
47 producer,editorial_department,miscellaneous tt0083658
48 camera_department,cinematographer,actor tt0083658
49 visual_effects,miscellaneous tt0083658
50 visual_effects tt0083658
51 camera_department tt0083658
52 visual_effects tt0083658
53 visual_effects,camera_department,cinematographer tt0083658
54 visual_effects,camera_department tt0083658
55 sound_department,editorial_department tt0083658
56 assistant_director,production_manager,producer tt0083658
57 editor,editorial_department,sound_department tt0083658
58 miscellaneous,producer,production_manager tt0083658
59 special_effects,art_department tt0083658
60 visual_effects,miscellaneous,animation_department tt0083658
61 costume_department,costume_designer tt0083658
62 editor,music_department,visual_effects tt0083658
63 costume_designer,costume_department,actor tt0083658
64 miscellaneous,actress,stunts tt0083658
65 special_effects,art_department,visual_effects tt0083658
66 miscellaneous tt0083658
67 costume_designer,costume_department,miscellaneous tt0083658
68 art_department tt0083658
69 casting_director,producer,miscellaneous tt0083658
70 art_department tt0083658
71 visual_effects tt0083658
72 music_department,sound_department,editorial_department tt0083658
73 costume_department,costume_designer tt0083658
74 visual_effects,producer,director tt0083658
75 visual_effects,miscellaneous,animation_department tt0083658
76 make_up_department,actor,special_effects tt0083658
77 special_effects tt0083658
78 sound_department tt0083658
79 camera_department,cinematographer,assistant_director tt0083658
80 art_department tt0083658
81 make_up_department tt0083658
82 sound_department tt0083658
83 writer,editor,director tt0083658
84 producer,assistant_director,production_manager tt0083658
85 visual_effects tt0083658
86 camera_department,visual_effects tt0083658
87 producer,writer,assistant_director tt0083658
88 art_department tt0083658
89 production_designer,art_director,art_department tt0083658
90 editorial_department,script_department,sound_department tt0083658
91 assistant_director,producer tt0083658
92 visual_effects tt0083658
93 visual_effects,producer,special_effects tt0083658
94 set_decorator,art_department,production_designer tt0083658
95 actor,archive_footage tt0083658
96 visual_effects,animation_department,miscellaneous tt0083658
97 music_department,composer tt0083658
98 visual_effects,producer,animation_department tt0083658
99 visual_effects,special_effects tt0083658
100 assistant_director,producer,miscellaneous tt0083658
101 art_department tt0083658
102 music_department,composer,actor tt0083658
103 camera_department tt0083658
104 art_department tt0083658
105 production_designer,art_department,art_director tt0083658
106 art_department,production_designer,art_director tt0083658
Thus, 135 people from the original are still alive. Some actor and actresses are still alive as well, so we may want to consider adding them in the plot as a “fan service,” such as the main actor Bruce Willis.
Task 7: Write and Deliver Your Pitch
For our next production, a remake of the 1988 Die Hard would be a strong competitor in the industry, starring Leonardo DiCaprio, Taylor Geare, and Tony Revolori. Directed by Academy Award winning Wally Pfister, the movie is bound to have an artistic expression like no other, similar to his eight other success. A guest appearance from Bruce Willis will have the fan base, who is practically begging for a remake, running to theaters.
From the 1990s to the 2000s, the Action genre experienced over a 350% growth in successes, becoming one of the most wanted and rewarding genre in the industry. With beloved actor Leonardo Dicaprio combining forces with innovative director Pfister and up-and-coming Geare, we will give Inception fans a wanted reunion in this remake, growing our anticipated fan base even further. Lastly, including young actor Revolori with resonate with the younger generation, especially those tied to Marvel, as he is a fan favorite in that sphere. Thus, this combination would be an absolute recipe for success, especially since the action genre has the most successes in the 2020s thus far! If we move forward with this plan, we can easily be the next success!