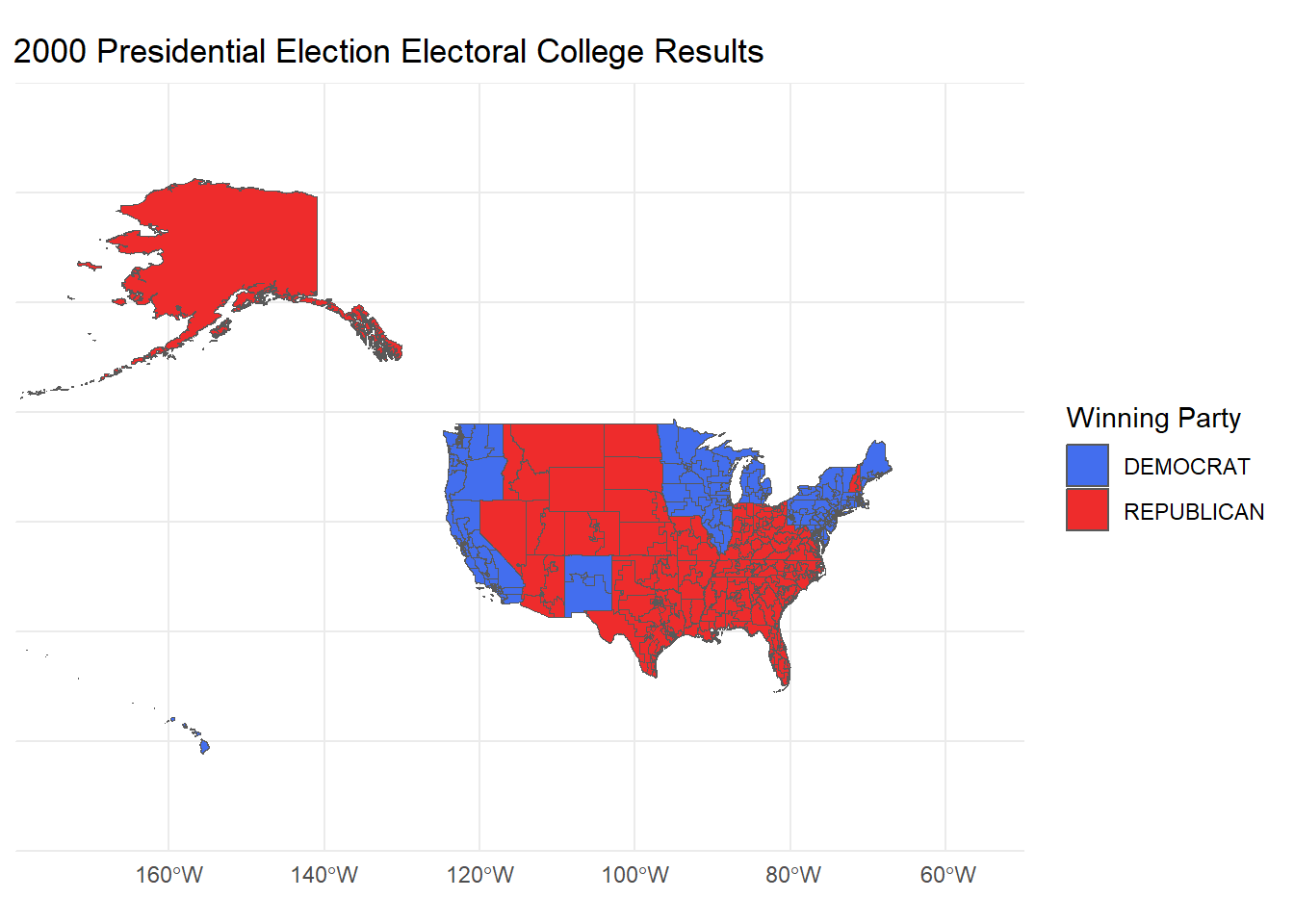
Mini-Project #03: Do Proportional Electoral College Allocations Yield a More Representative Presidency?
Introduction
In this project, I will be writing a political fact-check and investigate the claim that the US Electoral College systematically biases election results away from the popular vote.
Before we begin, we must download the code here. This code shows us how many votes each candidate got througout the years, for both the Presidential Elections and the House of Representatives Elections.
Click here to see how the data was downloaded into R
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Which states have gained and lost the most seats in the US House of Representatives between 1976 and 2022?
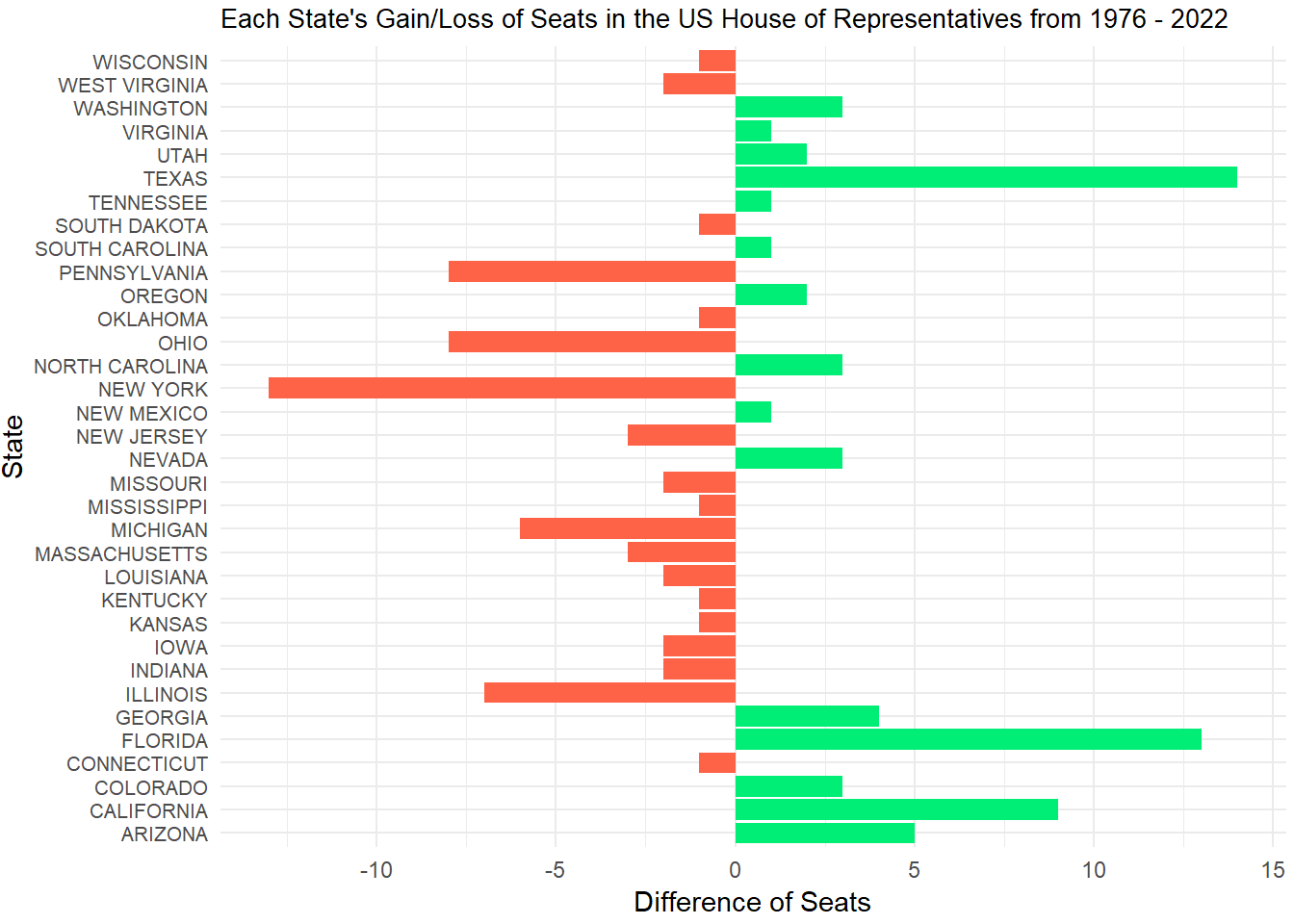
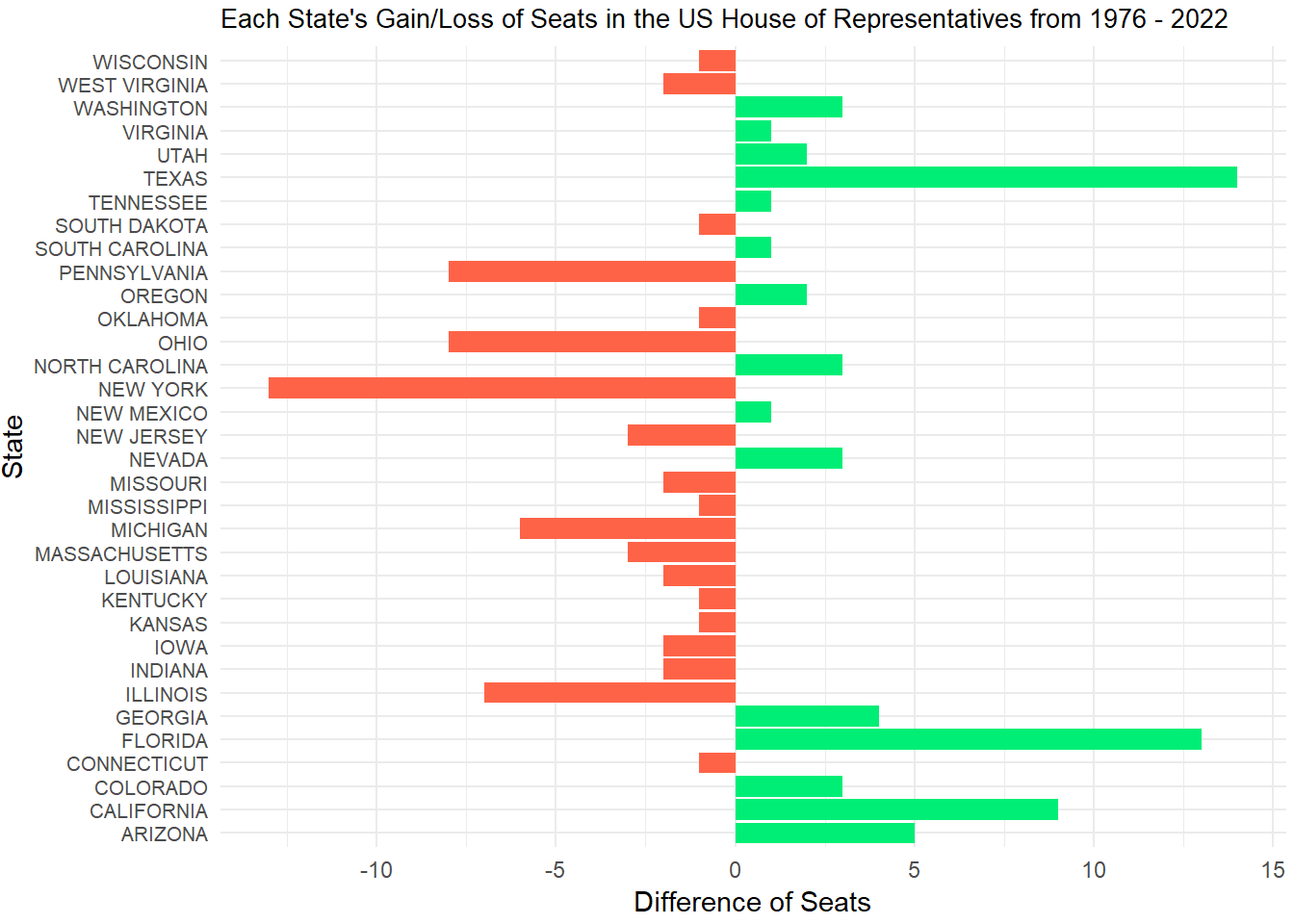
Firstly, I want to find out which states have gained and lost the most seats in the US House of Representatives between 1976 and 2022. To do this, I need to filter the House Seats data set to only show 1976 and 2022, then group it by year and state. Once I do this, I can find out how many distinct districts are in each state. For the purpose of this project, I will asign one seat per district in each state. Then, I can use these numbers to find the difference between the two years. Since many states actually had no change in seat numbers, I decided to exlude them from the data set and only show the states we are interested in. Thus, below is a bar graph that depicts either the gain or loss of House Seats from 1976 to 2022, per state.
`summarise()` has grouped output by 'year'. You can override using the
`.groups` argument.
house_seats_spread <- house_seats |>pivot_wider(names_from = year, values_from = seats) |>mutate(difference = (`2022`-`1976`)) |>filter(difference !=0)diff_seats <- house_seats_spread |>select(state, difference)ggplot(diff_seats, aes(x = state, y = difference, fill = difference >0)) +geom_bar(stat ="identity", show.legend =FALSE) +scale_fill_manual(values =c("tomato", "springgreen2")) +coord_flip() +labs(title ="Each State's Gain/Loss of Seats in the US House of Representatives from 1976 - 2022", x ="State", y ="Difference of Seats") +theme_minimal() +theme(plot.title =element_text(size =10),axis.text.y =element_text(size =8),plot.margin =margin(3, 3, 3))
Difference_in_seats <-ggplot(diff_seats, aes(x = state, y = difference, fill = difference >0)) +geom_bar(stat ="identity", show.legend =FALSE) +scale_fill_manual(values =c("tomato", "springgreen2")) +coord_flip() +labs(title ="Each State's Gain/Loss of Seats in the US House of Representatives from 1976 - 2022", x ="State", y ="Difference of Seats") +theme_minimal() +theme(plot.title =element_text(size =10),axis.text.y =element_text(size =8),plot.margin =margin(3, 3, 3))
print(Difference_in_seats)
Looking at this graph, we can see that Texas has gained the most seats and New York has lost the most seats since 1976. Notably, Pennsylvania, Michigan, Ohio, and Illinois all also lost over 5 seats, while California, Florida, and Arizona gained 5 or more seats. It is also interesting to see that more states lost seats than states that gained seats, with 19 states losing seats and 15 states gaining seats.
Are there any elections in our data where the election would have had a different outcome if the “fusion” system was not used and candidates only received the votes their received from their “major party line” (Democrat or Republican) and not their total number of votes across all lines?
Before computing this, we should understand what “The Fusion System” is. This system means that one candidate is allowed to appear on multiple “lines” on a ballot and their total votes are counted, rather than just appearing once. This gives this candidate an advantage, as they are practically running against themselves in other parties, but their total votes is counted against other candidates.
Now, I want to know if there are any elections in our data set that would have had a different outcome had the “fusion system” not been used. To do this, I am going to evaluate our data set at two different points: the first being with each candidates total votes, and the second using only “major party lines,” thus “DEMOCRAT” or “REPUBLICAN”. Then, I will find the winner of each side, and see if they line up. If the do line up, then the candidate who won was the true winner of the election. However, if they do not, then the “fusion voting” is what helped this person win over their competitor. This can be seen in my code below.
Warning in left_join(fusion_voting, no_fusion_voting, by = (c("state", "district"))): Detected an unexpected many-to-many relationship between `x` and `y`.
ℹ Row 1 of `x` matches multiple rows in `y`.
ℹ Row 1 of `y` matches multiple rows in `x`.
ℹ If a many-to-many relationship is expected, set `relationship =
"many-to-many"` to silence this warning.
Before showing the table, I want to note that there were 601 instances where this occurred! That is a lot of times that the fusion vote aided in a candidate’s win!
Below is a table that shows each of these instances.
library(DT)datatable(house_voting)
In this table, you can see the the difference in votes span from 61,938 to 559 votes over the 601 instances.
Do presidential candidates tend to run ahead of or run behind congressional candidates in the same state? Does this trend differ over time? Does it differ across states or across parties? Are any presidents particularly more or less popular than their co-partisans?
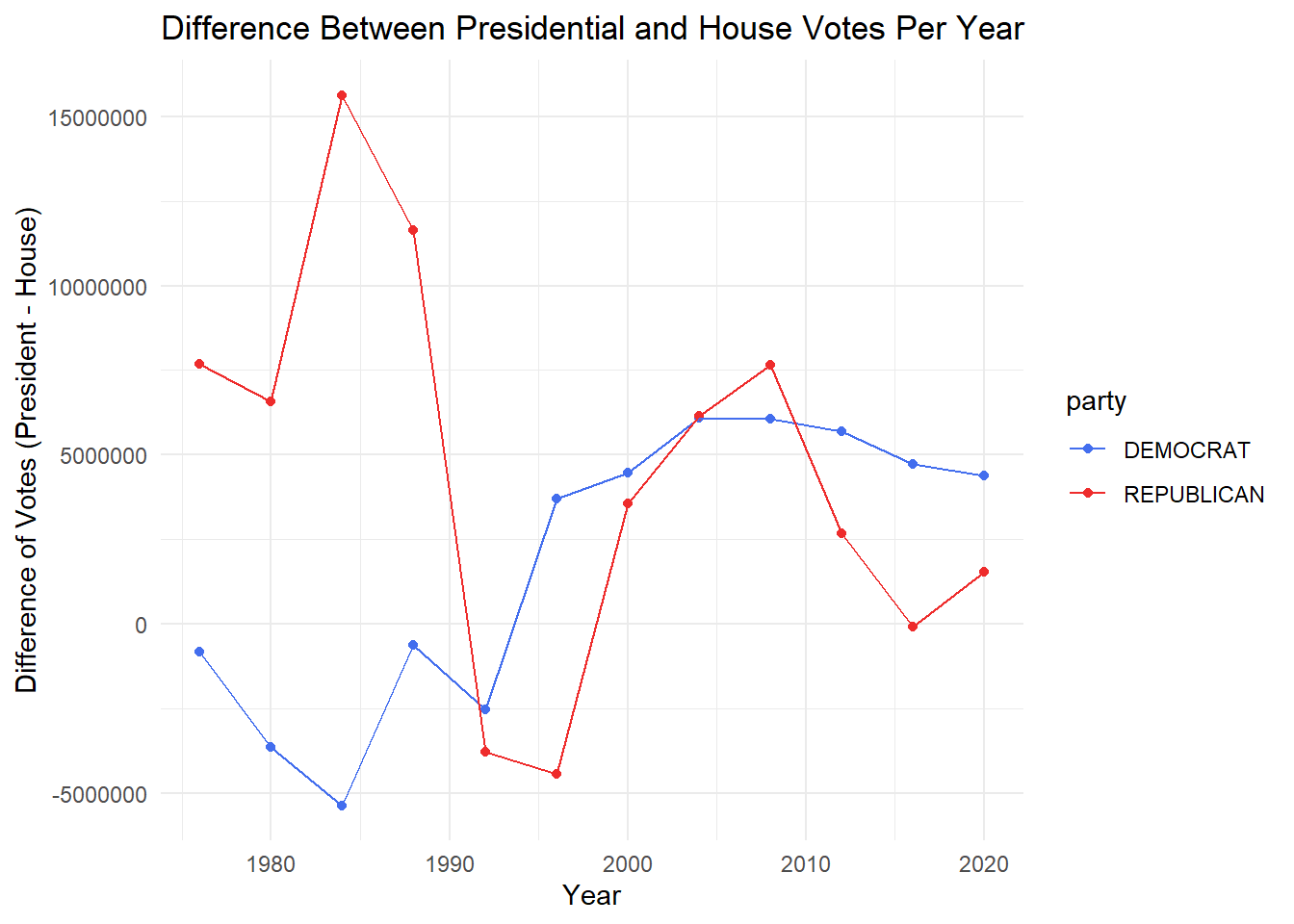
Now, let’s see if this trend differs overtime. To do this, I created a line graph to show the difference of votes between the President and the House, for both Republicans and Democrats. This can be seen below.
Click here to see how the code was done
house_candidates <- X1976_2022_house |>filter(party %in%c("REPUBLICAN", "DEMOCRAT")) |>group_by(year, party) |>summarize(total_votes =sum(candidatevotes), .groups ='drop') |>group_by(year, party)president_candidates <- X1976_2020_president |>filter(party_detailed %in%c("REPUBLICAN", "DEMOCRAT")) |>group_by(year, party_detailed) |>summarize(total_votes =sum(candidatevotes), .groups ='drop') |>group_by(year, party_detailed)colnames(president_candidates)[colnames(president_candidates) =="party_detailed"] <-"party"colnames(president_candidates)[colnames(president_candidates) =="total_votes"] <-"president_votes"colnames(house_candidates)[colnames(house_candidates) =="total_votes"] <-"house_votes"Vote_difference <- president_candidates |>inner_join(house_candidates, by =c("year", "party")) |>mutate(difference = (president_votes - house_votes))Overtime <-ggplot(Vote_difference, aes (x = year, y = difference, color = party)) +geom_point() +geom_line(linewidth = .5) +scale_color_manual(values =c("DEMOCRAT"="royalblue2", "REPUBLICAN"="firebrick2")) +labs(title ="Difference Between Presidential and House Votes Per Year", x ="Year", y ="Difference of Votes (President - House)") +theme_minimal()
print(Overtime)
Here, we can see that both parties has experience a large difference in votes. However, the Republican Party has tended to experience a higher support for their President over the House seats, while the Democratic Party has experienced both sides. Oddly enough, from about the 1990s - 2000s, the parties switched in their favor, with the House Republicans running more votes than the president and the Democrat President running more votes than the house.
To automate zip file extraction.
Click here to see how the data was downloaded into R
Installing package into 'C:/Users/laure/AppData/Local/R/win-library/4.4'
(as 'lib' is unspecified)
package 'plyr' successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\laure\AppData\Local\Temp\RtmpYlhbID\downloaded_packages
Installing package into 'C:/Users/laure/AppData/Local/R/win-library/4.4'
(as 'lib' is unspecified)
package 'sf' successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\laure\AppData\Local\Temp\RtmpYlhbID\downloaded_packages
library(sf)
Warning: package 'sf' was built under R version 4.4.2
Linking to GEOS 3.12.2, GDAL 3.9.3, PROJ 9.4.1; sf_use_s2() is TRUE
Warning in sf_column %in% names(g): Detected an unexpected many-to-many relationship between `x` and `y`.
ℹ Row 1 of `x` matches multiple rows in `y`.
ℹ Row 5 of `y` matches multiple rows in `x`.
ℹ If a many-to-many relationship is expected, set `relationship =
"many-to-many"` to silence this warning.
Though things have changed over time due to amendment, statue, and technology, the basic outline of allocation has remained the same:
Each state gets R + 2 electoral college votes, where R is the number of Representatives that state has in the US House of Representatives. In this mini-project, you can use the number of districts in a state to determine the number of congressional representatives (one per district).
States can allocate those votes however they wish
The president is the candidate who receives a majority of electoral college votes
Notably, the Constitution sets no rules on how the electoral college votes for a particular state is allocated. In the past, states have:
Direct allocation of ECVs by state legislature (no vote)
Allocation of all ECVs to winner of state-wide popular vote
Allocation of all ECVs to winner of nation-wide popular vote 2
Allocation of R ECVs to popular vote winner by congressional district + allocation of remaining 2 ECVs to the state-wide popular vote winner
To complete this fact check, we will compare the effects of all of the Electoral College Votes allocation rules. For this, we will assume that the District of Columbia has 3 Electoral College Votes.
First, let’s see who actually won each election throughout the years and how many electoral college votes they received to get this win.
`summarise()` has grouped output by 'year'. You can override using the
`.groups` argument.
datatable(country_winner)
Using this method, we can see that some elections would have turned out differently than what happened. For example, Gerald Ford would have won over Jimmy Carter in 1976, George H. W. Bush would have won over Bill Clinton in 1992, Robert Dole would have won over Bill Clinton in 1996, John McCain would have won over Barack Obama in 2008, and Mitt Romney would have won over Barack Obama in 2012. That is five elections over the past 46 years that would have been swayed due to this type of voting system.
I do not believe that this way of voting is fair, as it does not properly represent the voters of the minority party in each state. That is, if 51% of voters vote for Party A, while 49% vote for Party B, all of Party B’s voices will not be heard. That is a large majority of people who are being misheard. This also affects the election more, as the states who have less residents, but a good amount of electoral college votes can sway the election in their favor.
Thus, let’s go to the next voting option.
Allocation of all ECVs to winner of nation-wide popular vote 2
For the second option, this means that all Electoral College Votes are given to whoever wins the popular vote of the whole country.
`summarise()` has grouped output by 'year'. You can override using the
`.groups` argument.
datatable(country_winner2)
Using this method, there were only two instances where the winners here differ from the actually winners of each elections. The two scenarios are as follows: Al Gore would have won over George W. Bush in 2000 and Hillary Clinton would have won over Donald Trump in 2020.
Though this voting process produces similar outcomes to the actual election, I believe it is unfair due to the same reasoning as the first voting process. That is, again, if 51% of voters vote for Party A, while 49% vote for Party B, all of Party B’s voices will not be heard. That is a large majority of people who are being misheard.
Let’s go to the final method.
Allocation of R ECVs to popular vote winner by congressional district + allocation of remaining 2 ECVs to the state-wide popular vote winner
Warning in left_join(combined, X1976_2020_president, by = c("year", "state", : Detected an unexpected many-to-many relationship between `x` and `y`.
ℹ Row 6271 of `x` matches multiple rows in `y`.
ℹ Row 2 of `y` matches multiple rows in `x`.
ℹ If a many-to-many relationship is expected, set `relationship =
"many-to-many"` to silence this warning.
`summarise()` has grouped output by 'year'. You can override using the
`.groups` argument.
datatable(final_method_winners)
Using this method, we can see six elections would have had different outcomes than what would have actually occurred. These elections are as follows: Jimmy Carter would have won over Ronald Reagan in 1980, Walter Mondale would have won over Ronald Reagan in 1984, Michael Dukakis would have won over George H. W. Bush in 1988, Robert Dole would have won over Bill Clinton in 1996, Mitt Romney would have won over Barrack Obama in 2012, and Donald Trump would have won over Joseph Biden in 2020.
I do not believe this is fair, as it still gives the majority voters a competitive advantage in the voting process. Not only are they getting the majority of the votes from being the popular vote, but they are also getting two electoral college votes on top of that. Thus, I do not believe this is fair.
So What is the Best?
I believe the most fair way to divide the Electoral College Votes up in each state is on a proportional scale. Thus, each party is being accurately represented and no one party’s voice is being heard more than the other.
Citations:
MIT Election Data and Science Lab, 2017, “U.S. House 1976–2022”, Harvard Dataverse, V13
MIT Election Data and Science Lab, 2017, “U.S. President 1976–2020”, Harvard Dataverse, V8